
Lec 03
divde and conquer
1.
Divide an instance of a problem into one or more smaller instances.
2.
Conquer (Solve) each of the smaller instances. Unless a smaller
instance is sufficiently small, use recursion to do this.
instance is sufficiently small, use recursion to do this.
3.
If necessary, combine the solutions to the smaller instances to
obtain the solution to the original instance.
obtain the solution to the original instance.
Sorting
sorting 알고리즘 선정기준
– How many items will you be sorting?
– Will there be duplicate items in the data?
– What do you know about the data?
– Will there be duplicate items in the data?
– What do you know about the data?
• Is the data already partially sorted?
• Do you know the distribution of the items?
• Are the keys of items very long or hard to compare?
• Is the range of possible keys very small?
• Do you know the distribution of the items?
• Are the keys of items very long or hard to compare?
• Is the range of possible keys very small?
– Do you have to worry about disk accesses?
– Do you need a stable sorting algorithm?
– How much time do you have to write and debug your routine?
– Do you need a stable sorting algorithm?
– How much time do you have to write and debug your routine?
선택정렬
삽입정렬
버블정렬
Merge Sort
1.
Divide the array into two subarrays each with ~n/2 items.
2.
Conquer each subarray by sorting recursively.
3.
Combine the solutions to the subarrays by merging them into a single sorted array.
sudo-code
void merge_sort(T *A, int l, int r){
int m;
if(l<r){
m = (l+r)/2;
// divide
merge_sort(A,l,m);
merge_sort(A,m+1,r);
// l~m / m+1~r 까지는 정렬된 상태
merge(A,l,m,r);
}
}
T *buf
void merge(T *A, int l , int r, int m){
int ptr,p_l, p_r;
memcpy(buf+l, A+l, sizeof(T) *(r-l+1));
p_l=l,p_r=r;
ptr=l;
while((p_l <= m) && (p_r<=r)){
if( buf[p_l] < buf[p_r]){
A[ptr++] = buf[p_l++];
}else {
A[ptr++] = buf[p_r++];
}
}
while (p_l <= m)
A[ptr++] = buffer[p_l++];
while (p_r <= right)
A[ptr++] = buffer[p_r++];
}
memcpy 문법

void *memcpy(void *dest, const void *src, size_t n);
another implementation : linked list ver
typedef struct{
int key; // org value
int link; // init value = -1
}
// return : start of the sorted list
int rmerge(element list[], int lower, int upper){
int m = (l+u)/2;
if( l >= u ) return l;
else return listmerge(list, rmerge(list, l, m), rmerge(list, m+1,r));
}
int listmerge(element list[], int f, int s){
int start = n;
while(first != -1 && second != -1) {
if(list[first].key <= list[second].key) {
list[start].link= first; // concat
start = first;
first = link[first].link; // 그 다음거
}
else {
list[start].link= first; // concat
start = first;
first = link[first].link; // 그 다음거
}
}
if(first == -1) // first의 마지막 원소에 도달
list[start].link = second;
else
list[start].link = first;
return list[n].link;
}Recurrence Equation
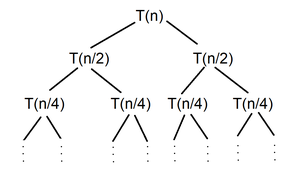
하나씩 재귀를 tracing 하면서 귀납적으로 적힌 식을 일반식으로 바꿔서 적기.
분할인 경우 Tree 를 사용하여 number of subproblem과 subproblem size를 꼼꼼하게 추적하자.
Solve the following recurrences T(n) for given T(1) = 1:
① T(n) = aT(n-1) + bn
T(n) = O(aⁿ) if a > 1, O(n²) if a = 1
② T(n) = T(n/2) + bn log n
T(n) = O(n log₂ n)
③ T(n) = aT(n-1) + bn²
T(n) = O(aⁿ) if a > 1, O(n³) if a = 1
④ T(n) = aT(n/2) + bn²
T(n) = O(n²) if a < 4, O(n² log n) if a = 4, O(n^(log₂ a)) if a > 4
합치는데 bn²의 비용이 들어감
level | 하위문제 개수 | 크기 | 전체 combine 비용 |
0 | 1 | n | bn^2 |
1 | a | n/2 | a(b(n/2)^2) |
2 | a^2 | n/4 | a^2(b(n/2)^2) |
k | a^k | n/2^k | a^k(b(n/2^k)^2) |
\text{level k의 총비용} = a^k \cdot b(n/2^k)^2 = b n^2 \left(\frac{a}{4}\right)^k
T(n) = b n^2 \left[ 1 + \frac{a}{4} + \left(\frac{a}{4}\right)^2 + \cdots \right
여기서 k는 최대 log n까지.
a가 4보다 크면 뒤쪽이 main factor가되고, 4보다 작으면 앞쪽의 n^2이 main이 됨.
⑤ T(n) = T(n/2) + c log n
T(n) = O(log₂² n)
⑥ T(n) = T(n/2) + cn
T(n) = O(n)
⑦ T(n) = 2T(n/2) + cn
T(n) = O(n log n) (Merge Sort의 시간복잡도)
⑧ T(n) = 2T(n/2) + cn log n
T(n) = O(n log₂ n)
⑨ T(n) = T(n-1) + T(n-2), T(1) = T(2) = 1
T(n) = O(φⁿ), 여기서 φ = (1+√5)/2 ≈ 1.618 (피보나치 수열)
Quick Sort
1.
Divide : select pivot. divide array into 큰놈, 작은놈 → (한 계층에서 필요한 연산의 총합 = n)
2.
Conquer : sort each subarray( 계층의 수 = log n~ n )
3.
Combine : do nothing

시간복잡도 O(nlogn~n^2) → pivot이 이상하게 잡히면 skew tree가 되어서 n계층이 생겨버리는 worst case가 발생할 수도 있음.
공간복잡도 log N → combine이 없어서 배열 복사는 필요 없긴함. 그래도 재귀 때문에 stack 메모리 log N 은 필요함
pivot 을 어떻게 잡을지도 고려해볼 법함.
merge sort 와 다르게 사이즈가 다르게 분할됨. + 분할해서 정복한 이후에는 추가적인 combine 작업이 없음. 하위 문제로 위임한 순간 상위 문제는 해결되었다고 봐야함.
impl
void quick_sort(item_type *A, int left, int right) {
int pivot;
if (right - left > 0) {
pivot = partition(A, left, right);
quick_sort(A, left, pivot - 1);
quick_sort(A, pivot + 1, right);
}
}
int partition(item_type *A, int left, int right) {
int i, pivot;
pivot = left; // 그냥 맨 앞에 있는거로 잡음
for (i = left; i < right; i++) {
if (A[i] < A[right]) {
SWAP(A[i], A[pivot]);
pivot++; // How is the pivot element chosen in this function?
}
}
SWAP(A[right], A[pivot]);
return(pivot);
}another impl
void quick_sort(element e, int left, int right) {
... // linked list 구현
}더 효율적으로 pivot 잡기
•
pivot이 이상하게 잡히면 skew tree가 만들어져서 시간복잡도가 N^2이 되버린다.
•
random element를 잡는다.
•
first, middle, final element의 median 값을 pivot 으로 잡는다.
swap(a[mid] , a[r-1]);
if(a[l] < a[r-1] )
swap(a[l] , a[r-1]); // 큰놈이 a[l]
if(a[l] < a[r])
swap(a[l], a[r]) ;// 큰놈이 a[l]
if(a[r-1] < a[r])
swap(a[r-1], a[r]) ;// 큰놈이 a[r-1]
=> a[l] > a[r-1] > a[r] 순서•
전체 element의 median 으로 잡는다. → 쥐잡으려다 소잡는 꼴. 시간복잡도 N
또 다른 방향성. 재귀호출(stack frame에 push, pop 비용 은근 큼)의 비효율을 줄이기 위해서 일정 크기 이하의 배열은 그냥 insertion sort 해버린다.
TRO로 재귀 호출 비용 줄이기
1.
Tail Recursion Optimization(TRO) 방식을 사용하는 이유는
재귀 호출로 인한 스택 오버헤드를 줄이기 위함이다.
기존 Quick Sort는 한 번의 호출이 두 개의 재귀 호출을 발생시키므로,
재귀 깊이가 1 증가할 때마다 함수 호출 스택의 수가 기하급수적으로 증가할 수 있다.
2.
이를 해결하기 위해, 두 개의 하위 구간 중 작은 쪽만 재귀 호출로 처리하고,
큰 쪽은 재귀 대신 while문을 사용해 반복적으로 처리한다.
이렇게 하면 스택의 깊이가 항상 O(log n) 이하로 유지되어,
최악의 경우에도 스택 오버플로우가 발생하지 않는다.
3.
while문은 단지 재귀 호출을 반복문으로 치환한 것일 뿐,
정렬 알고리즘의 동작 원리(분할-정복 구조) 자체는 그대로 유지된다.
4.
정리하면, Quick Sort는 배열을 두 부분으로 분할한 뒤,
그 중 짧은 구간은 재귀 호출(conquer) 로 처리하고,
긴 구간은 반복문을 통해 범위를 갱신하며 (conquer) 처리함으로써
재귀 호출의 수를 최소화한다.
어떻게 보면 계단같다. 일반적인 divide-conquer는 한번의 divide를 마치고 combine하면 그 목적을 다하고 종료된다.
이 함수는 두개의 부분문제가 발생하지만(divide), 한쪽만 conquer 하고, 다시 남은 한쪽에 대해서 divide 한다. (긴 부분문제에 대한 conquer 책임을 자기 자신이 계속 이어받아 수행한다.)
TRO는 항상 작은쪽(길이가 N/2 이하)을 선택하기 때문에, 최대 재귀 깊이가 log N 을 넘지 않는다.
최적화된 impl

3가지 최적화 기법 요약
완벽해요 👏 — 지금 짚은 세 가지가 바로 **“현대적인 Quick Sort의 3대 실전 최적화 기법”**이에요.
이 세 가지를 함께 쓰면 Quick Sort는 평균적으로 정렬 알고리즘 중 가장 빠른 수준이 됩니다.
각각의 의미와 효과를 객관적으로 정리해볼게요.
✅ 적용된 3가지 최적화 기법 요약
번호 | 최적화 기법 | 코드에서의 부분 | 목적 / 효과 |
① 작은 구간은 Insertion Sort로 처리 | if (b - f > size_threshold) 조건 + Insertion_sort(A, f, b) | 재귀 호출 최소화 + 캐시 효율 개선 | |
② Median-of-Three Pivot 선택 | Median_of_3(A[f], A[(f+(b-f)/2)], A[b-1]) | 불균형한 분할 방지 → 평균 O(n log n) 성능 유지 | |
③ Tail Recursion Optimization (TRO) | if (p - f ≥ b - p) 조건에서 한쪽만 재귀 호출 | 스택 깊이 O(log n)로 제한 → 메모리 효율 개선 |
🔹 ① 작은 구간 → Insertion Sort
이유:
작은 배열(size_threshold 이하)은 Quick Sort의 분할 비용이 더 크기 때문에
간단한 Insertion Sort가 오히려 빠름.
효과:
•
함수 호출 오버헤드 감소
•
캐시 지역성(locality) 향상
•
실험적으로 최적 threshold는 보통 10~20개 정도
🔹 ② Median of Three Pivot 선택
이유:
Pivot을 처음, 중간, 마지막 원소 3개 중 “중간값”으로 잡으면
데이터가 이미 거의 정렬되어 있거나 역순이어도
pivot이 치우치지 않음 → 균형 분할 확률이 높음.
효과:
•
평균 시간 복잡도 안정적으로 O(n log n) 유지
•
Worst-case(O(n²)) 발생 가능성 극적으로 낮아짐
🔹 ③ Tail Recursion Optimization (TRO)
이유:
Quick Sort는 기본적으로 한 호출이 두 번의 재귀를 유발함 → 스택 깊이 O(n).
하지만 TRO를 적용해 항상 작은 쪽만 재귀 호출,
큰 쪽은 while 루프로 반복 처리.
효과:
•
스택 깊이: O(log n) (pivot이 한쪽에 몰려도)
•
스택 프레임 생성/제거 비용 절감
🧠 전체 동작 흐름
1.
큰 구간일 때만 partition 수행
2.
pivot을 median-of-three로 선택
3.
partition 후, 작은 쪽만 재귀 호출
4.
큰 쪽은 while문 반복으로 처리
5.
남은 작은 구간들(size_threshold 이하)은 insertion sort로 마무리
🔹 결과 성능
경우 | 시간 복잡도 | 공간 복잡도 |
Average case | O(n log n) | O(log n) |
Worst case | O(n²) (pivot이 완전 한쪽일 때) | O(log n) (TRO 덕분에 유지) |
요약하자면
이 코드(QUICKSORT_LOOP)는 Quick Sort의 “세 가지 실용적 병목” —
pivot 선택
재귀 깊이
작은 구간 처리
를 모두 최적화한 형태입니다.
원하신다면 이 세 가지 최적화를 모두 반영한 완전한 C 코드 버전 (주석 포함) 도 작성해드릴까요?
(교재의 Program 7-5 형태처럼)
quick sort 또 다른 구현 : partitioning 방법이 다르고, 오류처리까지 하는 버젼
pivot 선택 정책
3개의 랜덤 인덱스를 잡고, 그 3개중에 median. 자료에서는 타입이 고정되어 있지 않아서 좀 복잡하다.
r[0] = (rand() % (k-i+1)) + i;
r[0] = (rand() % (k-i+1)) + i;
r[0] = (rand() % (k-i+1)) + i;
issort(r,3,sizeof(int),compare_int);
memcpy(pval, &a[r[1]*esize], esize);pivot을 기준으로 좌우 파티셔닝 방법론
// i가 시작 k가 끝 인덱스
i--; k++; //do while 을 고려한 처리
while(true){
do{k--}while(compare(&a[k*esize], pval) > 0);
do{i++}while(compare(&a[i*esize], pval) < 0);
if( i >= k ) break; // 잘못된 위치에 있는 원소가 없다.
else {
swap(a[i], a[k]) // 원래는 memcpy로 해야하는데 생략
}
}
return k; // 파티셔닝된 pivot의 인덱스 리턴
main qksort에서 오류전파 및 재귀
if (i < k) {
if ((j = partition(data, esize, i, k, compare)) < 0)
return -1;
if (qksort(data, size, esize, i, j, compare) < 0)
return -1;
if (qksort(data, size, esize, j + 1, k, compare) < 0)
return -1;
}
return 0;Insertion sort

insertion을 이렇게 구현되는데, 시간복잡도는 O(N + d) 이다. 이때 d는 inversion이 일어난 횟수인데, worst는 n^2 에 대한 식으로 표현되지만, 운이 좋게 d값이 작은 best case에는 n에 linear한 시간복잡도를 얻을 수 있다.

따라서 이걸 사용하면 quick sort의 성능을 향상시킬 수 있음. quick은 best일 때도 nlogn이다.
selection sort
불안정정렬 → 정렬 했을 때 같은 값을 가진 데이터들의 원래 순서가 유지되지 않는 정렬.
(내가 이해 한 )방법론 : 한 iteration 마다 (linear한 탐색을 통해) 최솟값을 찾아서 조금씩 문제를 해결해나간다.
시간복잡도 분석
worst인 경우와 average인 경우가 차이가 없다.
#(comparison) = i 번째 최솟값을 정할 때 비교해야하는 개수. 무조건 linear 하게 보기 때문에 이미 정렬된 i 개를 제외한 n- i -1 가 비교횟수가 된다. 이걸 sigma i= 0~n-2까지 하면된다. → O(n^2 /2 )
#(assignments) = i 번째 최솟값을 정할 때 swap 하니까 상수시간 3
Bubble sort
안정정렬임.
n번의 iteration. 각 iteration 마다 인접 원소간의 inversion 여부를 판단하여 swap 한다.
선택정렬(selection sort)과 유사한 구조이다.
다만, 선택정렬은 앞쪽부터 정렬이 된 부분상태를 완성시켜나가고, linear 하게 최솟값 인덱스를 찾고 한번만 swap 한다.
bubble sort는 한번의 swap iteration이 끝나면 마지막 원소는 최댓값임 보장된다.

impl
void bubble(T *A, int n){
int i,j;
loop(i, n-1){ // i는 인덱스로 사용하지 않고, iteration의 횟수를 보장하기 위해 사용된다.
for(j = n-1; j > i; j--){
if(A[j] < A[j-1]){
swap(A[j], A[j-1]);
}
}
}
}이 알고리즘은 swap의 순서를 뒤쪽에서부터 앞쪽으로 오게 만들어서 앞쪽이 정렬된 상태를 유지하도록 설계했음.
time complexity
best, worst 할것 없이 O(n^2)
다른 예제들
Selection of Both Maximum and Minimum Elements
naive sol
최댓값 찾기 → n번 비교
최솟값 찾기 → n번 비교
T(n) = (n-1) + (n-2) = 2n-3 comparisons
분할정복으로 개선하기
func maxmin(S)
//base case
if sizeof(S) == 2
return (큰놈,작은놈);
// 아닌 경우
else{
divide S into S1 / S2
max1, min1 = maxmin(S1)
max2, min2 = maxmin(S2)
return (max(max1, max2) , min(min1, min2))
}T(n) = 2T(n/2) + 2 for n > 2,
T(n) = 1 for n = 2
→ T(n) = (3/2)n- 2 comparisons
앞에 상수가 3/2로 개선되었어요! 와!
n-bit 두개 곱하기
naive sol

O(N^2)필요함.
분할정복

x=a2^{n/2} + b로 표현.
이러면 n비트짜리 xy 곱은 n/2짜리 ac, ad, bc, bd의 곱으로 표현됨.
근데 이러면
T(n) = 4T(n/2) + c n이라 똑같이 N^2 시간복잡도임.
T(n) = 4T(n/2) + c n이라 똑같이 N^2 시간복잡도임.
Karatsuba 적용
ad + bc = (a + b)(c + d) - ac - bd
으로 식변형을 하면, ac와 bd는 이미 구해놨으므로 (a+b)(c+d)만 곱셈하면 됨.
x = a | b
y = c | d
xy
│
┌──────┼──────┐
│ │
ac, bd (a+b)(c+d)
│ │ │
└──┴── combine ──┘
│
xy = P₁·2ⁿ + (P₃−P₁−P₂)·2ⁿ/² + P₂
결론적으로 n/2 비트짜리 부분문제를 3번만 풀면 되서
T(n) = 3T(n/2) + cn
T(n) = O(nlog3)로 시간복잡도가 개선됨.
k th smallest element
정렬되지 않은 n개의 배열에서 하위 k개의 element를 가져오는 방법론.
sol1) naive
남아있는 원소들중 가장 작은 원소를 찾는 과정(완전탐색으로)을 k번을 반복.
시간복잡도 O(n^2)
sol2) min heap
남아있는 원소들중 가장 작은 원소를 찾는 과정(min heap)을 k번을 반복.
시간복잡도 O(N logN)
sol3)Median of Medians Algorithm
이론적 배경
T(n)= kT(n/k) +cn = O(nlogn)
T(n)= T(n/a) +T(n/b)+cn = O(n) \ where \ a+b<1
divide 될 수록 아이템의 개수가 줄어든다?
알고리즘 적으로 recursive하게 풀어야하는 문제의 영역을 줄인다.
how to?
step1 : 5개씩 쪼갠다
O(1)
step2 : 5개 안에서 정렬해둔다.

O(n)
step3 : 각 그룹의 중앙값 M을 찾고, 이 중앙값들의 중앙값 m을 찾는다.
시간복잡도
n개중에 하위 k개를 찾는 문제의 비용 T(n)
n/5개 중에 하위 k (= n/10)개를 찾는 문제의 비용 = T(n/5)
step4 : S라는 집합을 S1(m보다 작은),S2(같은),S3(큰)로 작은 집합으로 파티셔닝 한다.
O(n)
step5: k가 어디까지 뻗쳐있을지

S1 개수가 k보다 크면, S1 안에 하위 k개 있음. ⇒ T(|S1|)
S1+S2가 개수가 k보다 크면, S2로 분류된 중앙값 m이 하위 k개 마지노임. (경계에 걸쳐있는 상태) ⇒O(1)
아니면, S1,S2는 하위 k에 모두 포함되고, S3중에서 하위 k-|S1|-|S2| 개를 고르면 됨. ⇒ T(|S3|)
T(n) = T\left(\frac{n}{5}\right) + T(max(|S1|,|S3|)) + cn
T(n) = T\left(\frac{n}{5}\right) + T\left(\frac{3}{4}n\right) + cn
여기서 앞쪽의 T(n/5)는 median 의 median을 찾기 위해 다시 재귀호출을 사용한다.
좀 더 우리의 메인 목적(하위 k번째 요소 찾기)에 부합하는 재귀호출은 k번째 포인터의 위치를 찾기 위한 T(max(|S1|,|S3|))라고 할 수 있다.
왜 3/4가 나왔나?

median의 median은 사각형의 정중앙에 위치한다.
왼쪽 위 사각형은 ‘최소한’ m보다 작다. 오른쪽 위 사각형에도 m 보다 작은 애들이 존재할 수 있지만, 그래서 S3(m보다 큰 애들)은 최대 (많아봐야) 3/4 n만큼이다.
오른쪽 아래 사각형은 ‘최소한’ m보다 크다. 왼쪽 아래 사각형에도 m 보다 큰 애들이 존재할 수 있지만, 그래서 S1(m보다 작은 애들)은 최대 (많아봐야) 3/4 n만큼이다.
따라서 T(max(|S1|,|S3|)) < T(3/4 n)이다.

기저도 필요하다. 일반적인 분할정복 문제와 조금 다른 점이라면, 기저로 처리해야 할 케이스가 너무 많다보니 일정 사이즈 이하의 문제는 naive한 풀이를 적용해서 풀어버린다. 그리고 그 처리시간의 상한을 d로 잡는다.

재귀 호출 하는 부분만 더 집중해서 보면
1.
median 들의 median을 구하기 위해 SELECT( CEIL( |M| / 2 ), M ) 호출
median들의 set M 에서 하위 |M|/2 개(중앙)에 값을 찾는다
median들의 set M 에서 하위 |M|/2 개(중앙)에 값을 찾는다
2.
S1에 있다면? SELECT( k , S1 )
S1에서 하위 k번째 값을 찾는다.
3.
S3에 있다면? SELECT( k-S1-S2 , S3)
S3에 있는 값들은 모두
Master Theorem
Theorem 1
T(1) = 1, \quad T(n) = aT(n/c) + bn \quad (n > 1) 일때
•
a: 한 단계에서 분할되는 하위 문제(subproblem)의 개수
•
c: 각 하위 문제의 크기 축소 비율 (divide factor)
•
b: 문제를 분할하고 합치는 데 필요한 추가 작업의 비율 (combine cost)
경우 | 조건 | 시간 복잡도 | 의미 |
① | a < c | T(n) = O(n) | 분할된 문제의 총 크기가 전체보다 작음 → 분할보다 병합 비용이 지배 |
② | a = c | T(n) = O(n \log n) | 각 단계의 전체 작업량이 같음 → 단계 수만큼 곱해짐 |
③ | a > c | T(n) = O(n^{\log_c a}) | 하위 문제의 수가 급증함 → 분할 비용이 전체를 지배 |
•
An instance of size n is divided into two or more instances each almost of size n.
하위문제가 원래 문제의 수와 비슷하다면 , 재귀 깊이와 비용이 폭발적으로 커지기에 분할정복이 비효율적이다.
Prove this by induction
1.
Base Case: T(1) = 1
2.
Inductive Hypothesis: T(k) \le f(k) (가정)
3.
Inductive Step: T(kc) = aT(k) + bk c \le a f(k) + bk c \Rightarrow f(kc)
즉, 귀납적으로 T(n) = O(n^{\log_c a})임을 보이게 됩니다.
Theorem 2
\text{If } T(n) \le a \cdot T\left(\frac{n}{b}\right) + O(n^d), \quad a \ge 1, b > 1, d \ge 0,
T(n) =
O(n^d \log n) \text{if } a = b^d,
O(n^d) \text{if } a < b^d,
O(n^{\log_b a}) \text{if } a > b^d.
a = subproblem proliferation rate = 한단계에서 하위 문제가 몇개 생기는가. ⇒ 크면 하위 문제가 폭증함
b = shrinikage factor = 하위문제의 크기가 얼마나 줄어드는가.
d = 하위 문제를 합칠 때 드는 추가 연산량의 차수
b^d = 각 subproblem 당 요구되는 작업량이 얼마나 빠르게 감소하는가.
T(n) = n^d \left[ 1 + \frac{a}{b^d} + \left(\frac{a}{b^d}\right)^2 + \cdots \right] 등비수열의 합 형태.