
Shane
Category
Empty
1.
OpenClaw was found to contain hundreds of skills that were laced with Trojans and data-stealing malware, which turned the AI agent into a malware delivery system and prompted mitigation actions by OpenClaw and VirusTotal.
2.
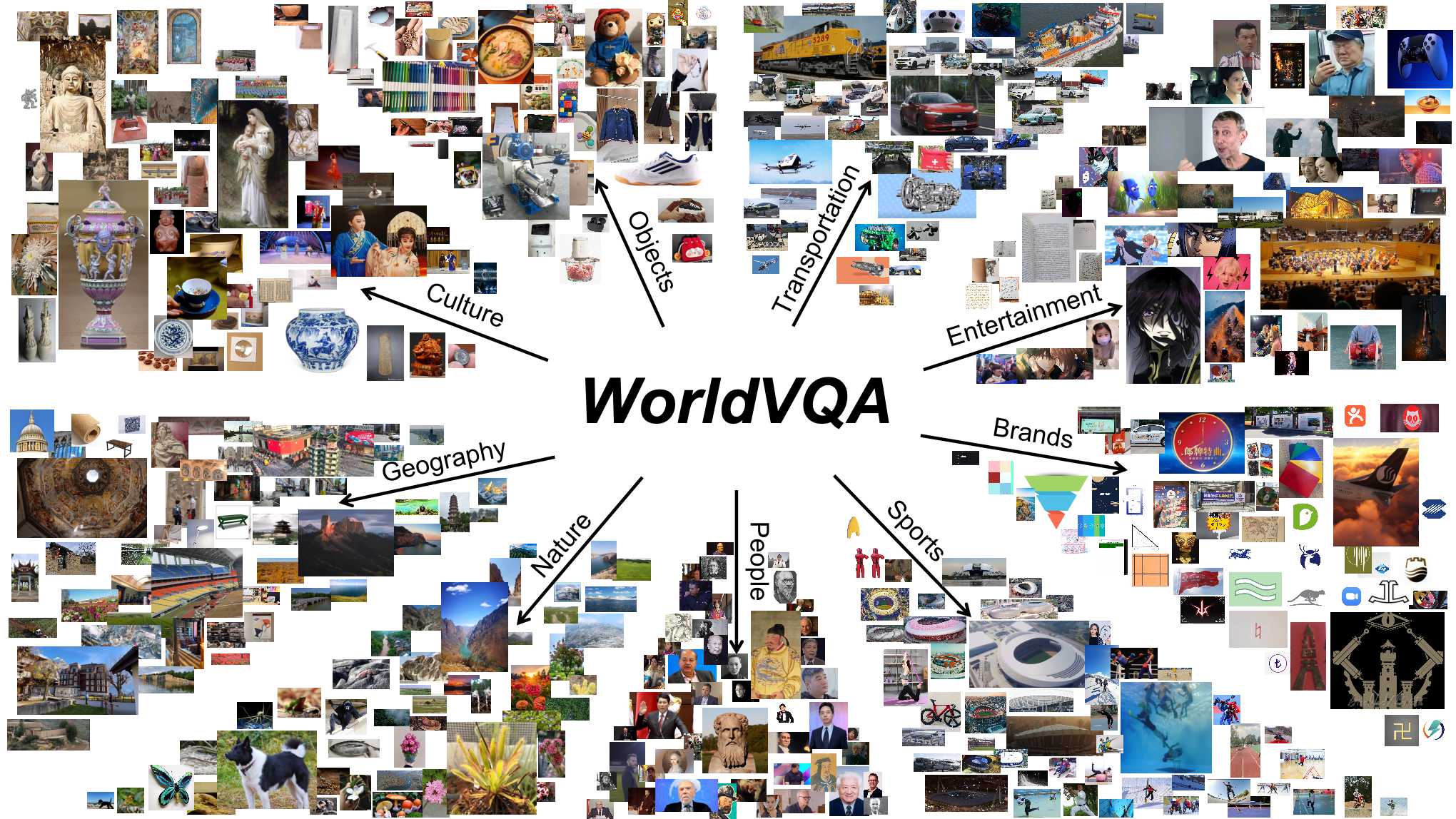
WorldVQA benchmark showed that leading multimodal models still failed to reach 50% accuracy on basic visual entity recognition, with Gemini 3 Pro scoring 47.4% and models often asserting incorrect specific labels with high confidence.
3.
Claude Opus 4.6 claimed the top spot on the Artificial Analysis Intelligence Index, surpassing GPT-5.2, while the report noted that OpenAI's Codex 5.3 remained pending and that Opus's token costs were higher than some competitors.
4.
Researchers reported that reasoning models such as Deepseek-R1 generated internal ensembles resembling teams of experts—a "society of thought" with contrasting internal voices—and that this internal debate measurably improved problem-solving performance.
References




more pain more gain 🚀
© 2024-2025 Shane "Lx". All rights reserved.